Improved Open Source Backup:
Incorporating inline deduplication and sparse indexing solutions
G. P. E. Keeling
< Prev
Contents
Next >
2. Software development methodology
Disclaimer: This methodology stuff is nonsense waffle required by the degree
course. My actual methodology was more like
this.
I generally followed the Agile method of XP ('Extreme Programming'), having
previously found that it worked reasonably well in a previous computer science
module.
Wells (2009) provides the following diagram, which gives a general outline of
the XP process.
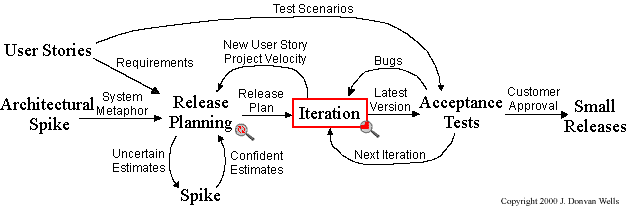
The coding was done on a Debian Linux platform, in C, although C++ was
considered. A major factor influencing this decision was my more extensive
experience with C, meaning that I would be able to utilise the limited time
more effectively, rather than dealing with problems arising out of C++
inexperience. However, a considerable effort was made to make sure that my
C structures followed object oriented principles. Another factor in the
decision to use C was that most of the original burp code was written in C,
albeit with the occassional C++ module for interfacing with Windows APIs.
Most of the testing during development was done on the Debian Linux platform,
with occassional testing using a Windows client cross-compiled with a mingw-w64
toolchain. This enabled quick progress whilst ensuring that nothing major
was broken on the Windows platform.
During the implementation of the second iteration in particular, once it was
clear that essential functionality would be complete before the project
deadline, a fair chunk of time was spent cleaning up existing burp code.
Code redundancy was reduced and old code started to be shifted towards a more
object-oriented approach. The structure of the source tree was
altered significantly in order to logically separate server and client code.
This was all done for the purpose of reducing 'technical debt',
which is very desirable from an Agile viewpoint.
2.1. Initial design decisions
I now needed to make some design decisions on exactly which algorithms
to use, and the changes that needed to be made to the design of burp to
support these new proposals.
However, I did feel that it was important to design the software in such a way
that I could easily switch between different choices of algorithms at some
point in the future. It is not actually greatly important to the design and
implementation of the software that I choose the best algorithms from the
start.
I chose MD5 for the strong checksum.
This was because I was familiar with it (and MD4) via experience with
rsync, librsync, and the original burp. The original burp uses MD5 in order to
checksum whole files. It is a suitable, low risk choice for strong chunk
checksums in the new software. An MD5 checksum also fits into 128 bits,
which saves on memory compared to something like the SHA family
(Eastlake, 2001) - which use a minimum of 160 bits - but still provides good
uniqueness. That is, two different chunks
of data are vastly unlikely to have matching MD5 checksums. For a match,
the blocks also need to have matching weak checksums, which further reduces
the chances of collisions.
At some future point, experimentation with other algorithms may be performed
though.
Lillibridge, M. et al, used their own Two-Threshold Two-Divisor chunking
algorithm (Eshghi, 2005), and assert that it "produces variable-sized chunks
with smaller size variation than other chunking algorithms, leading to
superior deduplication".
However, I chose 'rabin fingerprinting' (Rabin, 1981) for this task. It gives a
suitable weak checksum and the implementation that I produced seems suitably
fast, as will be seen in the test results.
Again, at some future point, experimentation with other algorithms may be
performed.
< Prev
Contents
Next >
|
