Improved Open Source Backup:
Incorporating inline deduplication and sparse indexing solutions
G. P. E. Keeling
< Prev
Contents
Next >
6. Initial test results
6.1. Software that did not complete the tests
backshift 1.20:
I had to 'disqualify' this software, because its first backup
took over 43 hours to complete. Most other software took less
than two hours for the first backup, so there was not much point in continuing
to test backshift. The raw figures for its first backup are included in
Appendix G.
It seems that backshift was suffering from the disk deduplication bottleneck
problem,
since it looked like it was using one file system node for each chunk that
it had seen, named in a directory structure after some kind of checksum. Due
to the way that it can only back up over the network on a network mounted share,
it was doing file system look ups for each incoming checksum over the network.
This must badly exacerbate the disk bottleneck problem.
Note from the author of Backshift, August 2015
obnam-1.1:
This software also had problems with the first backup
that meant there was not much point in continuing to test it.
It did not finish after eight hours, had taken up more
than 50GB of space on the server, and that space was rising. This was suprising
as there were only 22GB of small files to back up.
urbackup 1.2.4:
Although this software boasts an impressive feature list,
I was not able to complete the tests with it.
The main problem was that
restoring more than one file at a time was impossible, and even that had to
be done with point-and-click via its web interface. That made restoring a few
million files impractical.
The online manual states "the client software
currently runs only on Windows while the server software runs on both Linux
and Windows". However, at the time of running the tests, I did find source for
a Linux client, and its mode of operation was quite interesting and unique -
the server broadcasts on the local network, and backs up any clients that
respond. If this software gains better Linux support in the future, I think
it will be one to watch.
6.2. Software that did complete the tests
The rest of the software completed the tests.
I took the data and created a
series of simple graphs. The intention is to make it easy for the reader to
interpret the results.
I have also included the raw data from the tests in
Appendix G.
6.3. Areas in which the new software did well
In this section, I present the graphs representing the areas in which the
software developed in the first iteration did well. After that, I present the
areas in which the new software did not do so well.
In the graphs, I coloured the line representing the original burp red,
the line representing the new software green, and everything else grey.
This is so that it easy to see the change in performance over the original
burp whilst still enabling comparisons against other software.
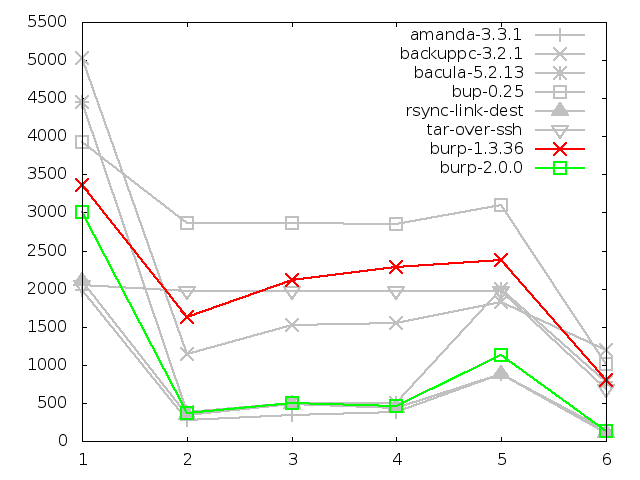
6.3.1. Time taken to back up
The time taken to back up was considerably improved over the original burp,
particularly in circumstances where lots of data changed between backups.
It was mostly faster than, or comparable to, other software in both small and
large file test sequences. The slight exception was the first backup that the
software makes, although even that is within an acceptable time frame.
I believe that this is because the software needs to checksum all the data
that it finds on its first run, and does not gain any advantage from time
stamp comparison of a previous backup. Software like tar (GNU, 1999) sends the
data
directly without calculating checksums, and will probably always win on a
fast network in terms of the speed of the first backup. However, it will
probably lose in terms of disk space used. Note also that, because amanda
(da Silva et al, 1991)
uses a special mode of tar to do its backups, its line closely follows that
of tar and does well in this test.
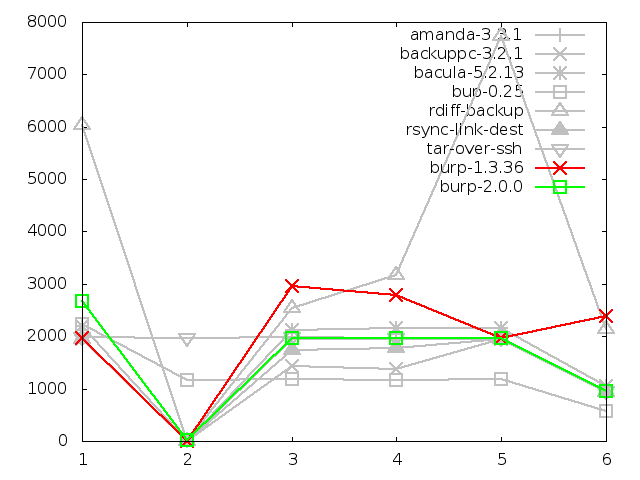
The software that was generally fastest at backing up the large file was
bup-0.25. However, it is notable that it didn't perform well when that file
had not been touched between backups (the second test in the sequence).
This is because although bup does
inline deduplication, it always reads in all the data, and doesn't do a check
on file time stamps. This may be of concern if your data set contains large
files that don't change very often - for example, iso images or movie files.
It is notable too that it was generally slower than most
software in the small files test.
In the first of the following graphs, I have excluded rdiff-backup because
its fifth and sixth backups took about 11 hours and 12 and a half
hours respectively. Since all the other software took less than 2 hours,
it was making the rest of the graph hard to read.
Time taken to back up small files, in seconds
Time taken to back up large file, in seconds
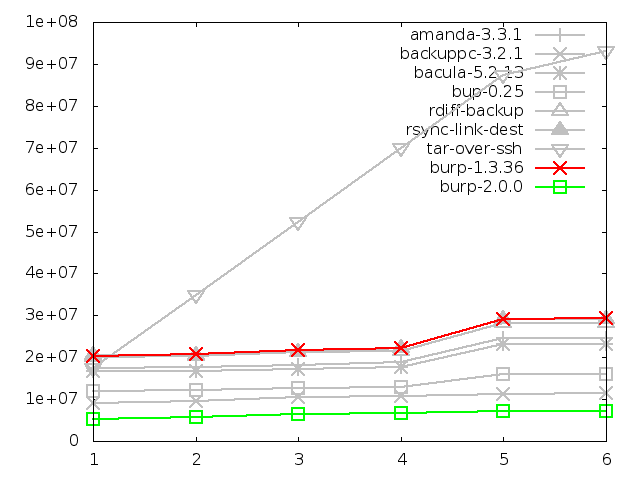
6.3.2. Disk space utilisation after backing up small files, in kbytes
The disk space utilised on the server after backing up small files was an area
in which the new software performed considerably better than the competition.
For both small and large file tests, it took up around 60% less space than the
best of its rivals.
The difference between the original burp and the new burp by the sixth test
in this graph is around 23GB.
I have to admit that I was expecting bup-0.25 to do a bit better than it
actually did in this test. It is very gratifying that the new software used
about half the space that bup did, because bup was the only remaining contender
with an inline deduplication feature.
Backuppc also performed impressively well, falling in the middle between bup
and burp-2.0.0. The file-level deduplication that it uses appears very
effective on the data set.
One more notable thing about this graph is that it clearly shows the
disadvantage of backing up all the files every time - tar uses about 93GB of
space in the end.
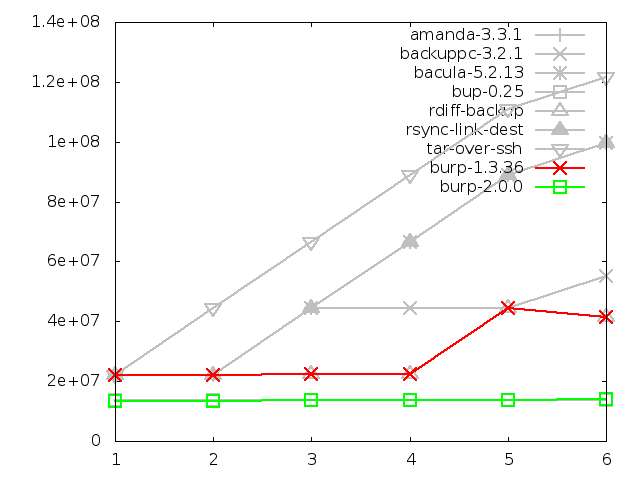
6.3.3. Disk space utilisation after backing up large file, in kbytes
The disk space utilised on the server after backing up the large file was
another area in which the new software performed better than the other
contenders - that is, except for bup-0.25. This is not completely obvious
on the graph because the two lines are on top of one another.
In fact, they are so close that burp-2.0.0 uses less space for the first three
backups, and then bup-0.25 uses less for the last three. After the sixth
backup, there is only 181MB between them. Note that bup-0.25
actually stores some files on the client machine as well as the server,
which is something that no other software does.
This graph clearly demonstrates the weaknesses of software that has to store
changed files as complete lumps. Again, tar does particularly badly, but this
time so do amanda, backuppc (Barratt, 2001), bacula and rsync, all lying on
almost exactly the same line not far beneath tar.
Once more, backuppc's file-level deduplication performs surprisingly
effectively as it identifies the file with the same content at step four
(timestamp update without changing file contents) and step five
(rename).
Finally for this test, burp and rdiff-backup perform identically. This is
because they are both saving old backups as reverse differences with librsync.
6.3.4. Number of file system entries after backing up small files
For the small files, the new software used fewer file system nodes than the
'link farm' solutions by
several orders of magnitude, which is to be expected. It was comparable to
the non-'link farm' solutions. This is because it can pack the chunks from
many small files into far fewer data files.
Creating the largest 'link farm' by far was rsync, which is to be expected
because in '--link-dest' mode, it creates a mirror of the source system for
every backup. You may have noticed rsync performing consistently well in the
speed results, but this is really where it falls down as a versioned backup
system, because the number of file system nodes becomes unmanageable.
Here, there are eight million nodes for six backups.
I am somewhat surprised to see the original burp do better than the other
'link farm' solutions. On reflection, it must be because it has a mechanism
whereby older backups do not keep a node referencing a file that is identical
in a newer backup.
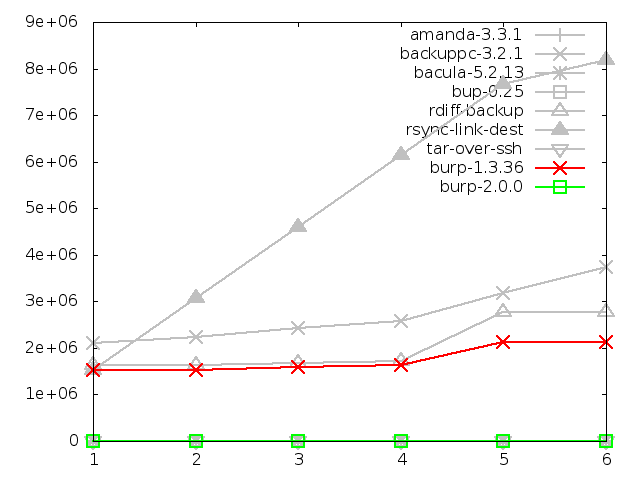
6.3.5. Number of file system entries after backing up large file
For large files, it is notable that the new burp creates more nodes than
all the other solutions.
This is because chunks making up the file need to be split over
several data files, whereas the 'link farm' solutions will only use one node.
Also, it appears that the inline deduplication of bup-0.25 packs its chunks
into fewer, larger data files than burp-2.0.0.
At first glance, this doesn't look like a good result for burp-2.0.0.
However, in reality, it is more than satisfactory,
because it still only used a manageable figure of around 1000 nodes for the
large file tests anyway.
Further, this figure will not vary very much if identical data were spread
across multiple files and then backed up - whereas software using a node
for each file would increase linearly with the number of files.
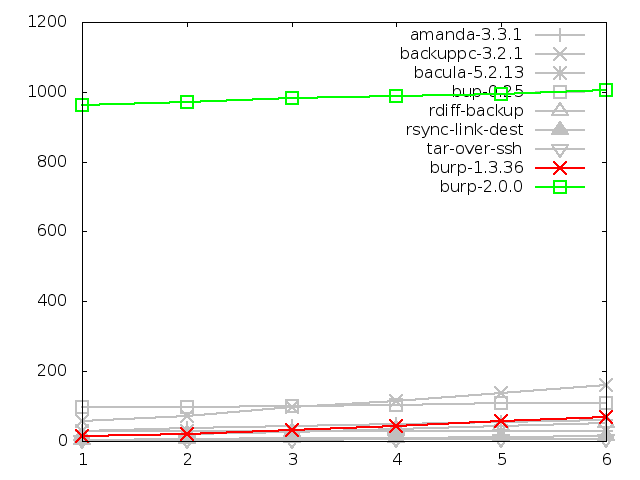
6.3.6. Network utilisation when backing up small files, in bytes
When backing up small files, the new software
performed better overall than other solutions in terms of
network utilisation during backup. This is because the way that it deduplicates
means that it only needs to send chunks that the server has not previously
seen.
If you look closely (or check the raw data), you can see that amanda, backuppc,
bacula, bup, and rsync all beat it at steps two,
three, and four. I am not entirely sure why this might be. Perhaps it is
because burp sends a complete scan of the file names and statistics for
every backup, and maybe the other software have a more efficient way of doing
the same thing. This deserves investigation at some future time.
However, this is more than made up for by the massive differences between
the new software and the nearest rival at steps one and five, where it uses
less than half the bandwidth of bup-0.25.
Also worth pointing out with this graph is the strange behaviour of backuppc
on its last backup, where I would have expected the figure to drop, as all
the other backups did. At first I thought this was a transcription error,
but the figure in the raw data looks plausible, and different from the figure
at step five. I cannot explain this, and it may be worth testing backuppc
again to see if this behaviour is repeated.
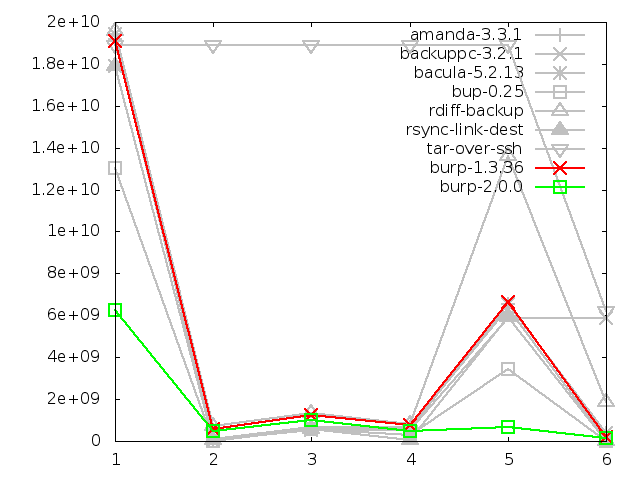
6.3.7. Network utilisation when backing up large file, in bytes
Once more, the new software generally performs better than the competitors in
terms of network utilisation when backing up large files, with the exception
of bup-0.25, which is so close it overlaps with burp-2.0.0's line.
What jumps out at me from this graph is how badly all the software except
the inline deduplicators (bup-0.25 and burp-2.0.0) do when the file to
back up is renamed (step five) - this causes them to send 25GB across the
network, as opposed to burp-2.0.0's 290MB, and bup's very impressive 63KB.
In fact, I have to concede that, if you look at the raw figures, bup clearly
performs the best in this test, with burp-2.0.0 a few hundred megabytes behind.
It should be noted though that there is a massive void between burp-2.0.0 and
the next nearest competitor.
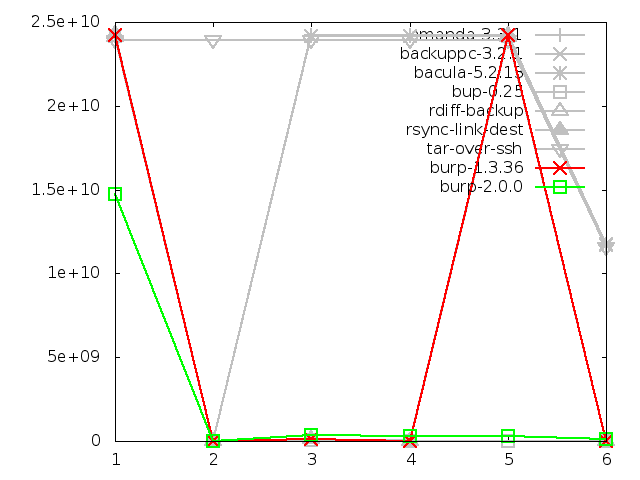
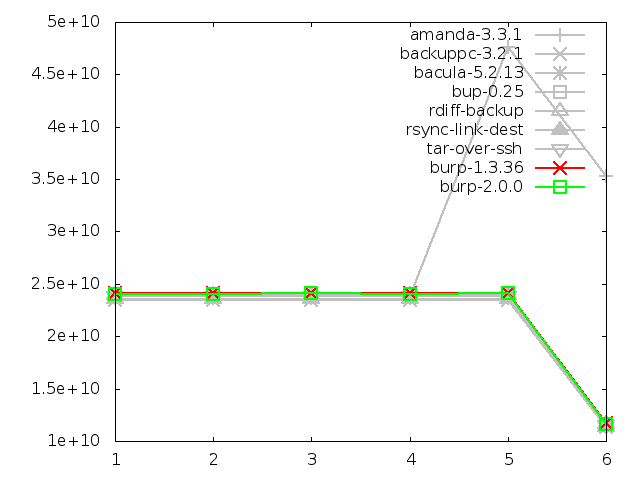
6.3.8. Network utilisation when restoring small files
We find that the new software was comparable to the other solutions in terms of
network utilisation during restore, and all the solutions except amanda
followed a nearly identical path.
Tar did the best in the category, although
the difference was minor. I believe that burp's performance here could be
considerably improved by sending the blocks and instructions
on how to put them together instead of a simple data stream. There is more
on this idea in the 'future iterations' section of this report.
The other notable remark to make about this test was the strange behaviour
of amanda on the later restores, where it suddenly leaves the path set by
all of the other software and the network usage shoots up.
Amanda has an odd tape-based mentality, and on disk, it creates files that it
treats like tapes, with one backup per tape (file).
When you ask it to restore all files from incremental backup 5, it will go
through each previous 'tape' in turn, and restore everything that doesn't
have an identical name in a subsequent backup. If a file was deleted in
a subsequent backup, it will delete the file that it just restored.
In the case of the large file test, this means that nothing odd happens
until the file is renamed in step 5. When restoring that, amanda first restores
the original file name, then deletes it and restores the renamed file. Since it
restored two large files, the network utilisation is high.
This is clearly very inefficient behaviour when you have the ability to seek
to any point in a disk much faster than you can with tapes.
Network utilisation when restoring small files, in bytes
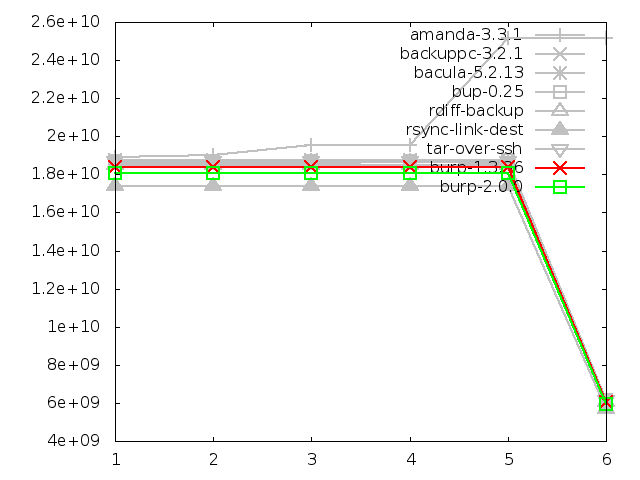
Network utilisation when restoring large file, in bytes
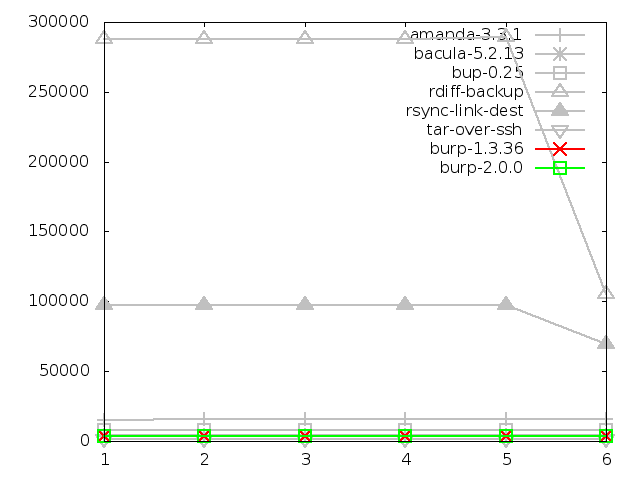
6.3.9. Maximum memory usage of client when restoring small files
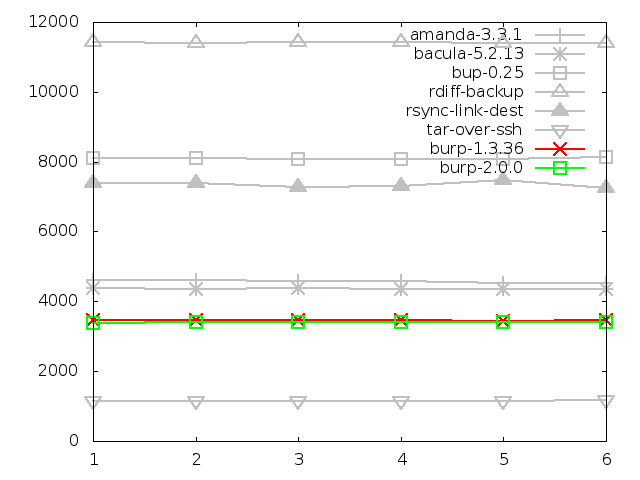
Before analysing the data in the graphs in this category, it should be noted
that, for the software that uses ssh for its network transport mechanism,
the memory usage of ssh itself was not captured. At the very least, this would
add a few thousand KB to their figures.
The software that this should be considered for are amanda, backuppc, bup,
rdiff-backup, rsync and tar. All of them except bacula and burp, which have
their own network transport mechanism.
With this in mind, it should be clear from the following graphs that both
the original and new versions of burp perform the best in terms of memory
usage on the client side during restores. The client restore mechanism
didn't change between the two burp versions, but the server side restore did.
This is demonstrated in the next section.
Note also that I was unable to measure the client memory usage of backuppc
during the restore, so it doesn't appear in the graphs. However, the result
would have been equivalent to tar over ssh, since that is the mechanism that
backuppc uses to restore files on Linux.
Coming out badly in the small file category were rsync and, in particular,
rdiff-backup which did three times worse than rsync. For the large file
category, there wasn't actually much material difference between the
contenders.
Maximum memory usage of client when restoring small
files, in kbytes
Maximum memory usage of client when restoring large
file, in kbytes
6.4. Areas in which the new software did not do so well
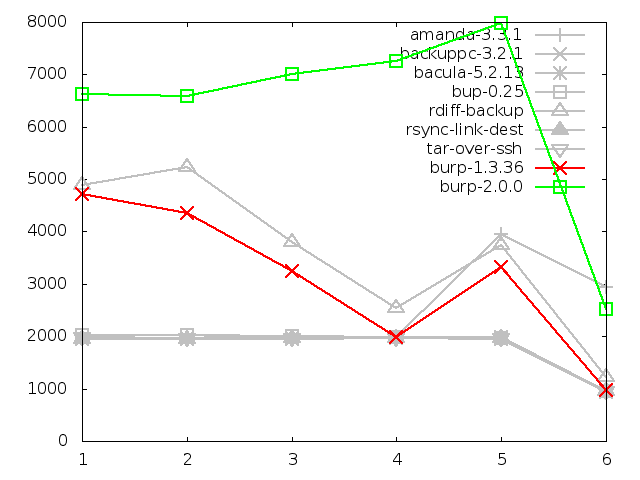
6.4.1. Time taken to restore
Firstly, the time taken to restore files takes twice as long as the original
burp, and at least four times as long as solutions like tar and rsync that are
not having to reassemble files from disparate chunks in a selection of storage
files.
This is to be somewhat expected. It could be argued that, since a restore
happens far less often than a back up, that this state of affairs is
acceptable - time regularly saved during backing up is likely to exceed the
time spent waiting longer for an occasional restore. Nonetheless, I will
attempt to improve the restore times in later iterations because it is
understood that people want to recover quickly in a disatrous situation.
A result that I found unexpected here was the impressive speed of bup-0.25,
which is in the same region as tar and rsync. Since bup, like burp-2.0.0, has
to reassemble chunks from its storage, I was expecting it to be slow. So how
does it manage this? A probable reason for this kind of performance can
be found in the later section about server memory usage.
Time taken to restore small files, in seconds
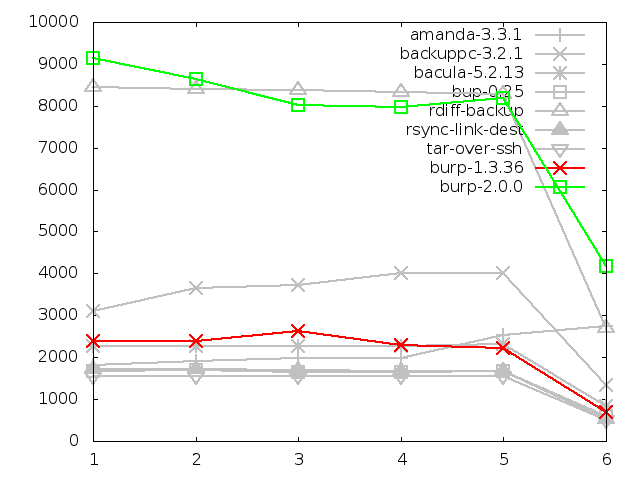
Time taken to restore large file, in seconds
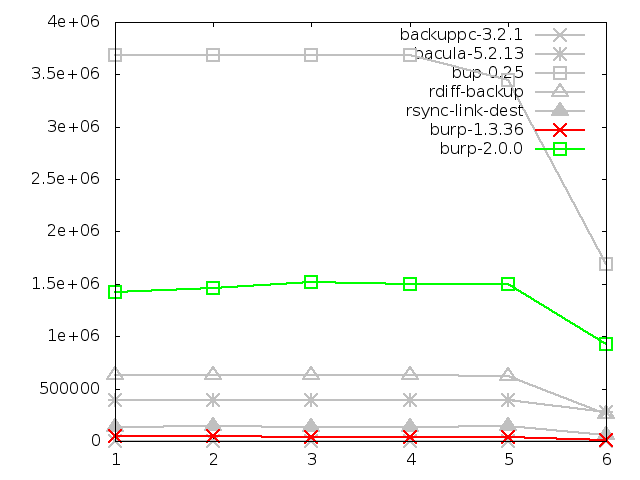
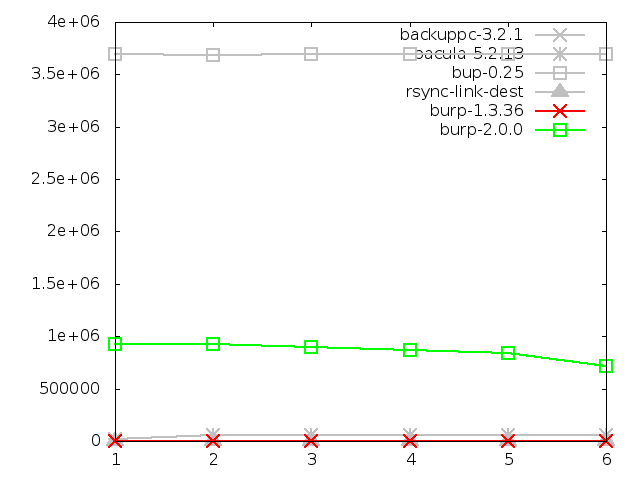
6.4.2. Maximum memory usage of server when restoring
This is an area in which bup-0.25 does spectacularly poorly, using up all
the memory available on the server. This is how it manages to restore so
quickly, because it must be loading all of the chunks it needs to send into
memory. By that, I mean all of the data and probably a full index of all the
checksums as well. This means that it can look up each chunk to send very
rapidly, making it nearly as fast as software that only needs to send the
data without doing any lookups.
The memory usage of bup-0.25 (or more specifically, the 'git' backend that
it uses to do the heavy work) is so bad that it makes burp-2.0.0 look
reasonable by comparison, when it really isn't. If bup were not being tested,
burp-2.0.0 would be the worst performer by a large margin, using 1.5GB
consistently.
This is something that I will attempt to improve in the second
iteration, by improving the storage format and lookup algorithms so that
the server holds less data in memory at any one time.
Tar is missing from the graphs because I was unable to capture the server
ssh memory usage. Although, as it was the only server process running, it
would have used minimal memory anyway.
Amanda is also missing from the graphs. Due to the complexity of the multiple
child processes involved in an amanda
restore, I was not able to capture server memory figures for it. I would
estimate, based on knowledge of how it works, that its memory usage would be
minimal.
And rdiff-backup is also missing from the graphs. I was unfortunately unable to
capture figures for it when restoring large files, despite several repeated
attempts.
Maximum memory usage of server when restoring small
files, in kbytes
Maximum memory usage of server when restoring large
file, in kbytes
6.4.3. Maximum memory usage of server when backing up small
files, in kbytes
The memory usage of the new software when backing up small files is an
area in which the new software, although not the worst performer, has scope
for improvement.
This is because it is loading all the chunk checksums that
it has ever seen, and their locations, into memory in order to perform the
inline deduplication. The second iteration of the new software will attempt
to mitigate this by implementing sparse indexing. This will mean that only
a small percentage of checksums and their locations will be loaded into memory.
It is notable that the original burp does very well in this test. It generally
holds a minimal amount of data in memory, and when reading files, it tends
to fill a fixed sized buffer and process it straight away, rather than reading
the whole of the file into memory. Other solutions doing well were amanda,
bup-0.25, and rsync.
Some might observe that bacula is not doing well on any of the server
memory tests. It has a severe handicap in this area, because it relies on
a mysql database process, which was measured as part of its tests.
There are large peaks on the first step and the fifth step (rename) for
rdiff-backup, showing that it uses far more server memory when there are new
files to process.
Tar is missing from the graphs because I was unable to capture the server
ssh memory usage. Although as it was the only server process running, it
would have used minimal memory anyway.
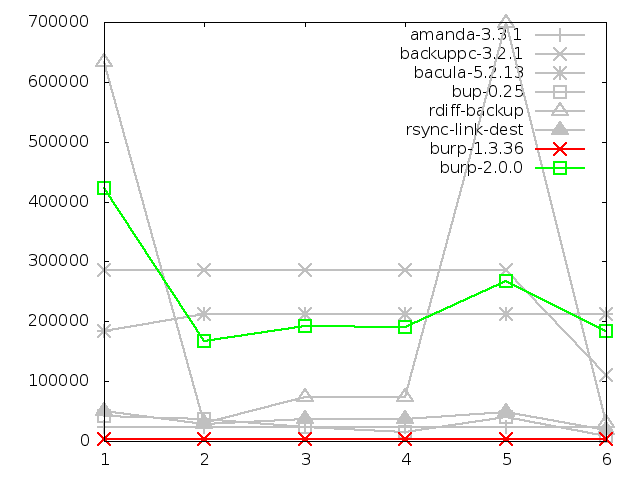
6.4.4. Maximum memory usage of server when backing up large
file, in kbytes
This is clearly an area in which burp-2.0.0 does spectacularly poorly, using
seven times as much memory as bacula, the next worst out of the contenders.
Again, this is because it is holding a full index of all the checksums in its
memory, and this is something that will be addressed in the second iteration
by implementing sparse indexing.
All the other software, except bacula, performed in a similar range to each
other. There are obvious peaks for bup-0.25 when there are new file names
to process, but it never gets worse than bacula. The original burp does very
well.
Tar is missing from the graphs because I was unable to capture the server
ssh memory usage. Although as it was the only server process running, it
would have used minimal memory anyway.
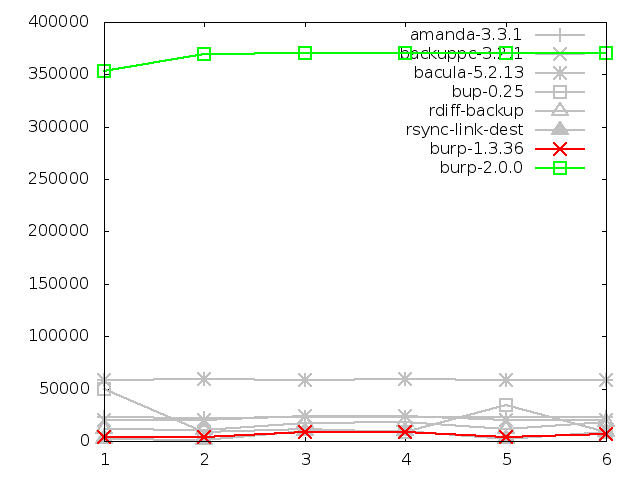
6.4.5. Maximum memory usage of client when backing up small
files, in kbytes
As with the server memory usage, this is an area in which the new software
performs badly.
It has high memory utilisation because, for each file
that the server asks for, the client has to load all the chunk data and their
checksums into memory. It keeps them in memory until the server asks for them,
or indicates that it doesn't need them. There is a built in limit to this
already - the client will keep a maximum of 20000 blocks in memory at once.
When it reaches this limit, it will not read in any more until it is able
to remove at least one of those blocks from memory.
Perhaps of some concern is the peak in memory usage on the first backup of
each sequence, when I was expecting the line on the graph to be flat. I am
currently unable to explain this - it may indicate some kind of memory leak.
I will address this again later in the report.
After its first backup, bacula does poorly. I believe that this may be because
the server sends the client a list of all the file names that it has seen
before in order to deduplicate on time stamps, and the client holds them in
memory.
Again, all the other software perform within a similar range to each other.
Missing from the graph are amanda and backuppc, for which I was unable to
get figures. However, since they both use tar over ssh in order to retrieve
files from clients, it is fair to say that they would have performed similarly
or even identically to the results for tar.
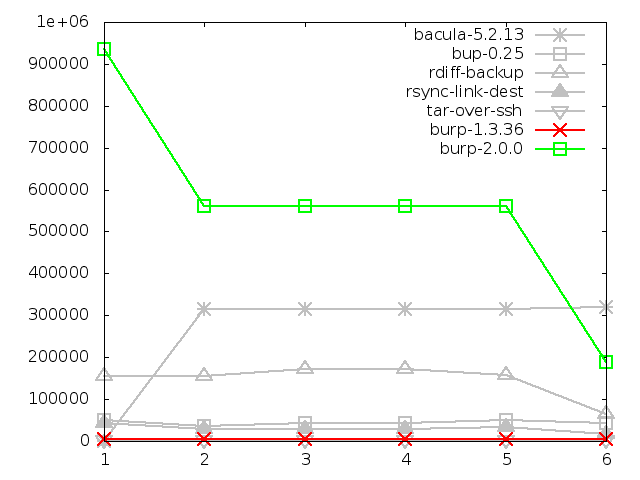
6.4.6. Maximum memory usage of client when backing up large
file, in kbytes
Finally, the new software performed badly at steps 1 and 3 (altered file
contents). At steps 4, 5 and 6, it performed similarly to the second worst
software in this area, bup-0.25. It did beat bup-0.25 at step 2, where bup's
lack of file level time stamp checking meant it had to read the whole file
in again.
The rest of the software performed within a similar range to each other, with
tar being the best in this field. Bacula showed a strange peak at the last
step (file trunaction), taking its memory usage above that of bup-0.25 and
burp-2.0.0. I don't have a sensible explanation for this.
Missing from the graph are amanda and backuppc, for which I was unable to
get figures. However, since they both use tar over ssh in order to retrieve
files from clients, it is fair to say that they would have performed similarly
or even identically to the results for tar.
 < Prev
Contents
Next >
< Prev
Contents
Next >
|
