Improved Open Source Backup:
Incorporating inline deduplication and sparse indexing solutions
G. P. E. Keeling
< Prev
Contents
Next >
8. Final test results
Upon implementing the design changes in the previous section, the new software
was retested and graphs produced that demonstrate the changes in performance.
The graphs are the same as in the original testing, except that a new blue line
for 'burp-2.0.1', the new software, has been added.
Firstly, I present the results for which the new software previously did
well.
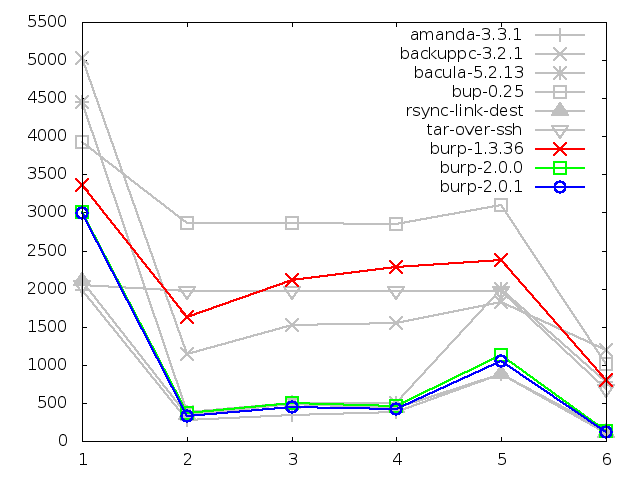
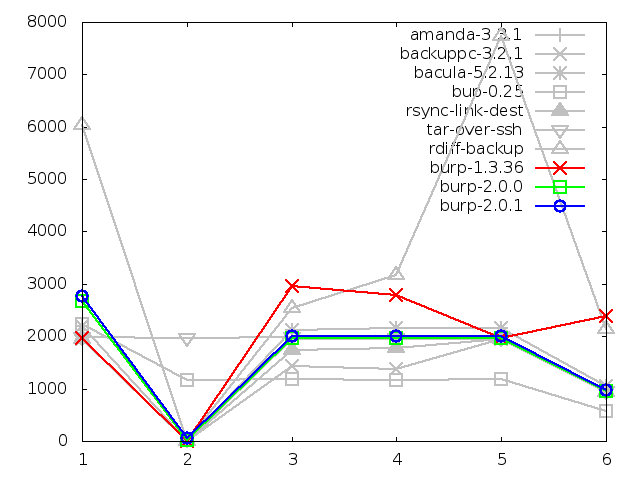
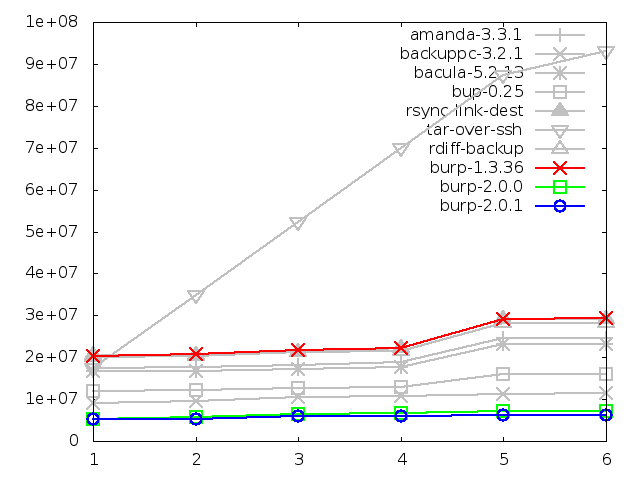
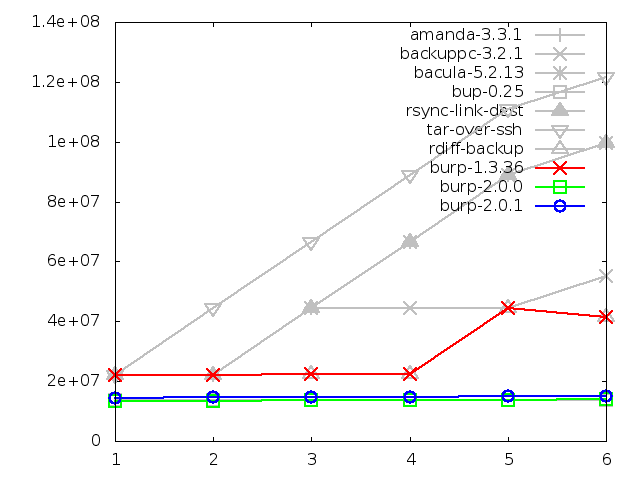
This will demonstrate that, for those, that good level of performance remained
unchanged after the second iteration. These graphs generally need no commentary
because that has already been done adequately in the chapter on the initial
results.
After that, I present the results for which the new software previously did
poorly and look for whether the second iteration made any significant change,
either good or bad.
8.1. Areas in which the second iteration continued to do well
Time taken to back up small files, in seconds
Time taken to back up large file, in seconds
Disk space utilisation after backing up small files, in kbytes
Disk space utilisation after backing up large file, in kbytes
Number of file system entries after backing up small files
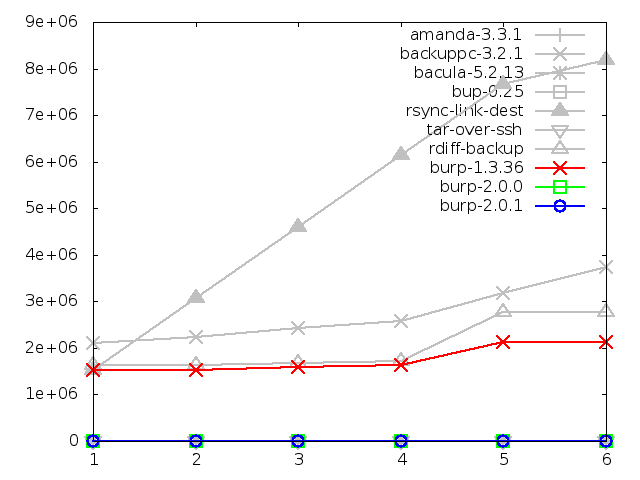
Number of file system entries after backing up large file
The second iteration clearly affected the results here, with each backup
adding a little fewer than 1000 new file system nodes.
The reason for this is that the design of the second iteration split up the
manifest files (containing information on how to reconstruct each backed up
file out of blocks) into multiple smaller pieces. This was done in order to
be able to have a sparse index for each of the smaller manifest pieces, rather
than a full index on every block that has ever been seen.
Although the change in the graph looks dramatic, there are still less than
5000 file system nodes in use by the last backup. As explained previously,
this figure will not vary very much if identical data were spread
across multiple files and then backed up - whereas software using a node
for each file would increase linearly with the number of files (note the
test results for file system nodes when backing up many small files).
Consequently,
I am happy to maintain that this is still a good result for the new software.
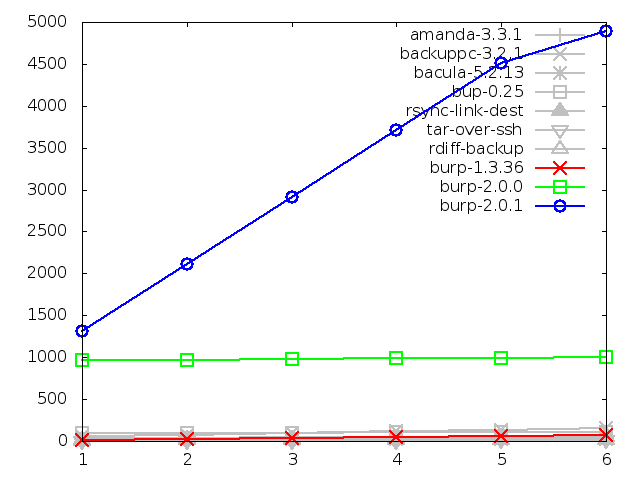
Network utilisation when backing up small files, in bytes
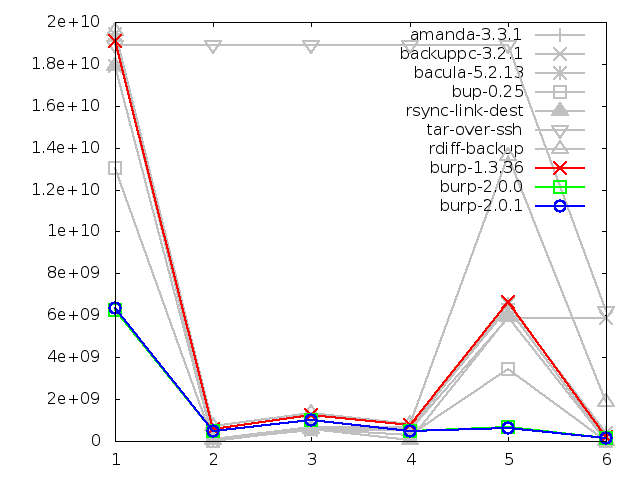
Network utilisation when backing up large file, in bytes
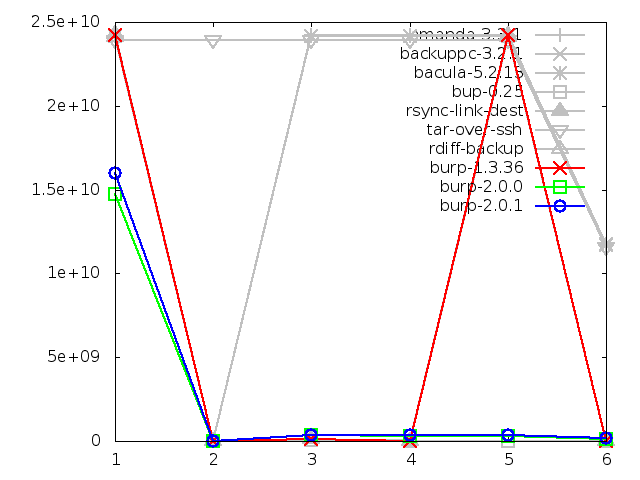
Network utilisation when restoring small files, in bytes
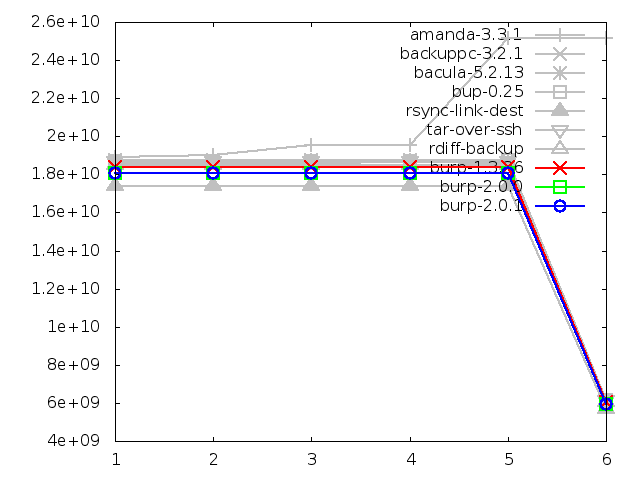
Network utilisation when restoring large file, in bytes
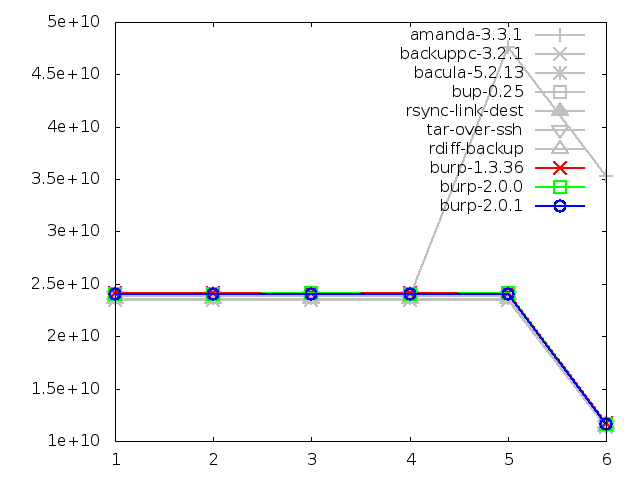
Maximum memory usage of client when restoring small
files, in kbytes
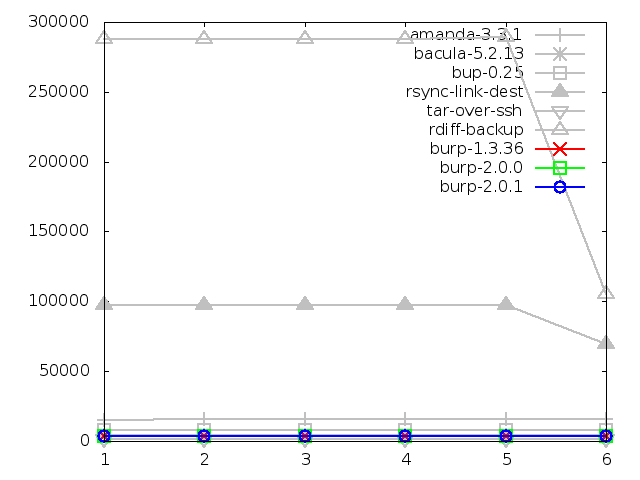
Maximum memory usage of client when restoring large
file, in kbytes
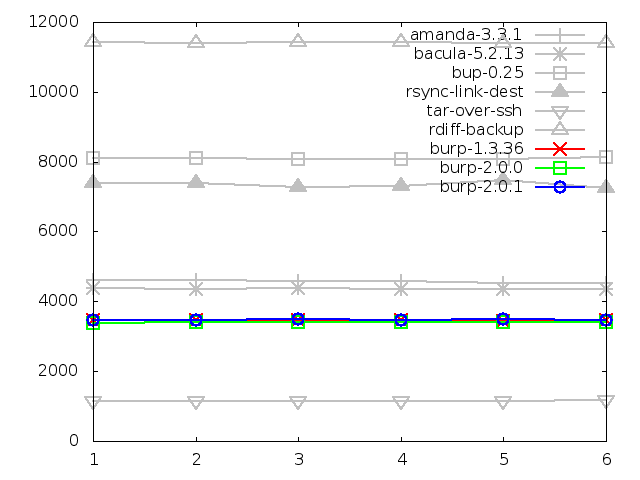
8.2. Areas in which the second iteration showed improvement
8.2.1. Time taken to restore small files, in seconds
The time taken to restore small files was improved slightly. I cannot give
any particular reason for this, other than perhaps improving code efficiency
between the two versions. Note that the benefit of sparse indexing only relates
to backing up, not restores.
On reflection, there was some work focused on factoring out functions related
to reading and writing manifest files into a class-like structure. This, at
least, improved ease of maintenance.
Another reason for the improvement could possibly have been due to the changes
in the structure of the data storage, getting rid of the signature files
and holding them only in the manifests. I didn't expect this to improve the
speed when I did it, because the first iteration didn't look at the signature
files on restore anyway. However, maybe there was an efficiency improvement
there that I overlooked.
Regardless, although the test showed improvement in this area, the new software
is still not doing well when compared to the other solutions.
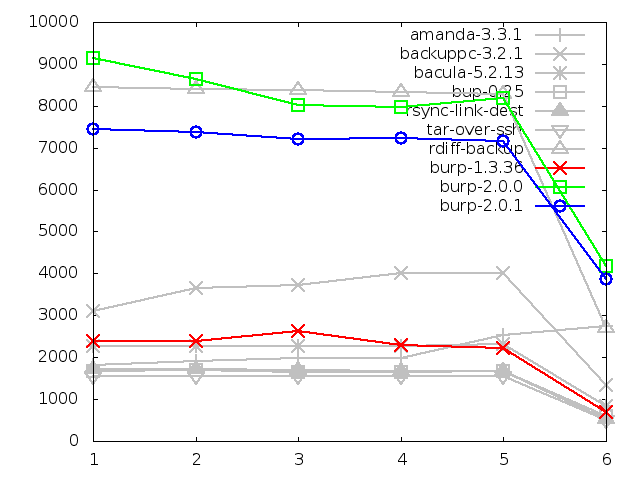
8.2.2. Time taken to restore large file, in seconds
The time take to restore the large file had a much more significant improvement
than that for the small files.
My thoughts on the reasons for this obviously echo the speculation in the
previous section to do with improved code efficiency and the changing storage
structure.
However, although there was a large improvement, the new software is still
not doing particularly well in this category.
The following chapter on further iterations proposes a possible method of
improving the restore times, and describes my initial implementation of that
method.
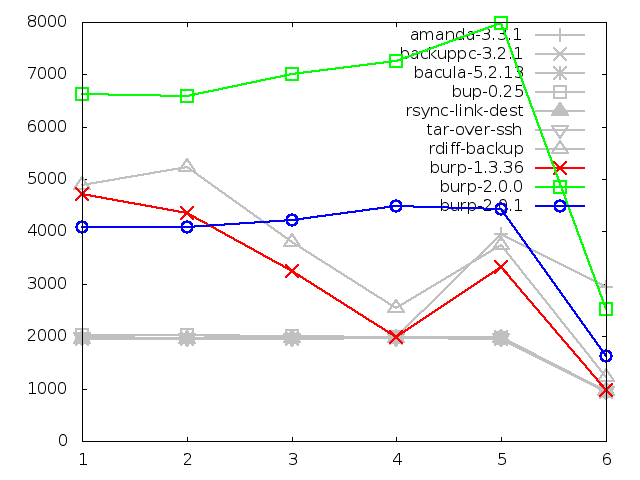
8.2.3. Maximum memory usage of server when restoring
There is significant improvement in the second iteration for both large and
small file restores in terms of server memory usage.
The small file memory was reduced to a third of the original result, and the
large was halved. This is excellent.
Both sets of figures are now comparable with each other. This seems to suggest
that the original iteration had some sort of memory problem relating to client
file names, because there really shouldn't be much difference between the
memory usage for restoring lots of small files and restoring a large file -
the server is just sending a stream of blocks being read from a similar number
of manifest files.
The memory for small files has now dropped below bacula's figures. I don't
think that this can be improved further without altering the method for restore,
as explained in the following chapter about further iterations.
Maximum memory usage of server when restoring small
files, in kbytes
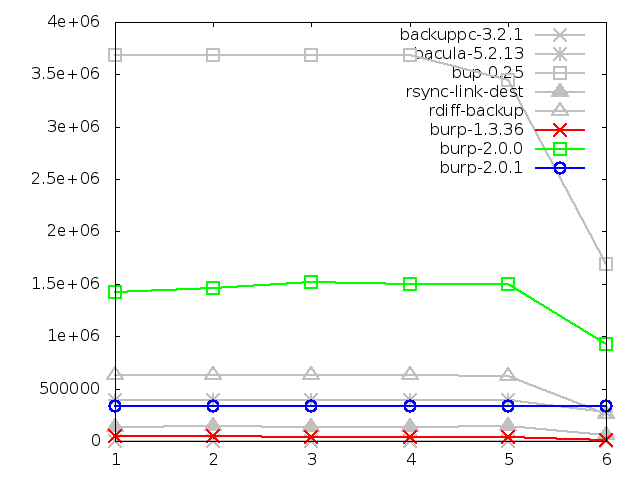
Maximum memory usage of server when restoring large
file, in kbytes
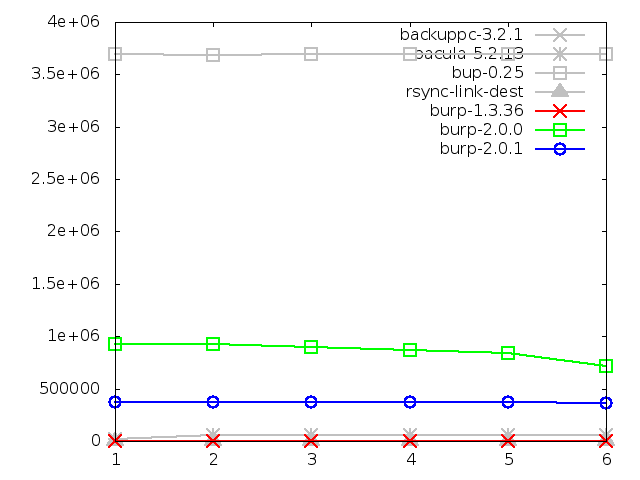
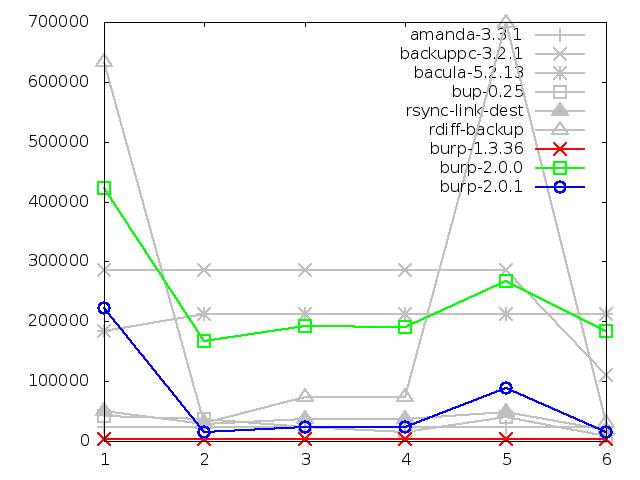
8.2.4. Maximum memory usage of server when backing up
This is the area in which I had hoped to see improvement due to the addition
of the sparse indexing feature. Rather than loading a full index into memory,
the server will load a much smaller sparse index, then only fully load the
manifest pieces that have a high chance of matching the next incoming blocks.
And indeed, in both small and large file restores, there is significant
improvement. And this time, it brings the new software to a comparable level
with the better group of its competitors. This is excellent.
The only problem that I have with this is that there are peaks in the small
backup at steps one and five (renames). I believe that this is something to
do with the way that the server receives the file system scan and deals with
new file names. I have a potential solution to this that I will describe in
a later chapter.
Maximum memory usage of server when backing up small
files, in kbytes
Maximum memory usage of server when backing up large
file, in kbytes
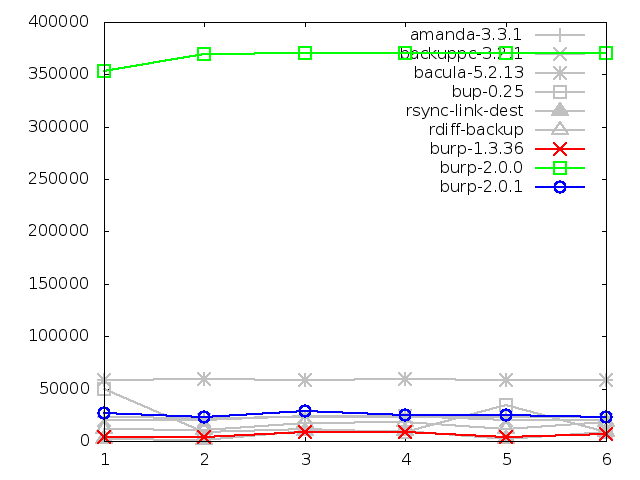
Important note: the graph above is showing that the memory usage of the
server has been limited by the implementation of sparse indexing. In conjuction
with the results showing that the disk space use changed negligibly
between iterations and that the time taken actually decreased, this indicates
that sparse indexing is an effective alternative to keeping a full index in
memory, and hence also an effective solution to the disk deduplication
bottleneck.
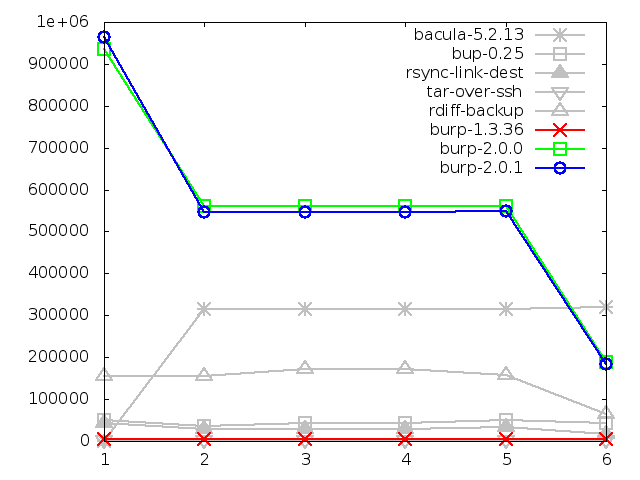
8.3. Areas in which the second iteration performed badly
8.3.1. Maximum memory usage of client when backing up small
files, in kbytes
The results for this test did not change to any significant degree. This is to
be expected, since no changes were specifically made in the second iteration
to improve this.
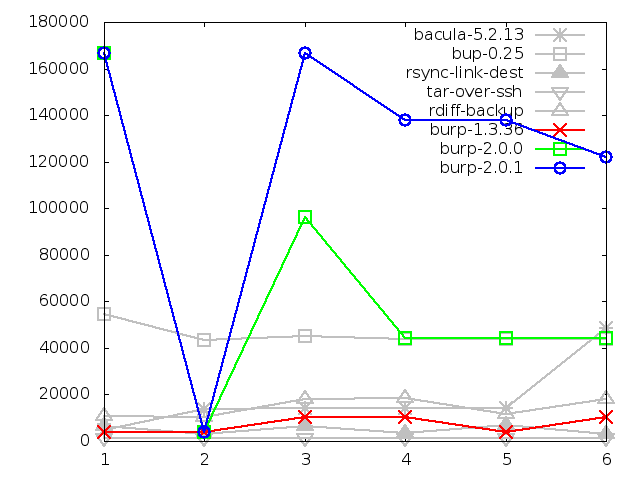
8.3.2. Maximum memory usage of client when backing up large
file, in kbytes
Finally, we come to the worse result of all. When backing up large files, the
situation actually became worse after the second iteration. I was expecting
the results to remain similar to the previous iteration.
However, on reflection, there is a reasonable explanation for this behaviour.
When backing up, the client reads data into memory, splitting it into blocks
and checksumming them. It then needs to keep the blocks in memory until the
server has told it either to send or to drop them.
The code limits the client to keeping 20000 blocks in memory at once.
The blocks are an average of 8KB each, according to the parameters input into
the rabin algorithm. 20000 x 8KB = 160000KB, which matches the peaks we see
in the graph.
My theory is that, for the first iteration, the server was fast enough at
processing incoming blocks that the client only ever loaded the maximum amount
of blocks at some point during the first backup. And, after the second
iteration, the server was slowed down slightly by having to load the right
pieces of manifest based on the sparse index, giving the client a chance to
fill up its memory with more blocks.
If this is really the case, a future possibility is to experiment with reducing
the number of blocks that the client will keep in memory at any one time.
Without changing anything else, this could be as low as 4096 blocks - the
number that the server is currently counting as a segment to deduplicate.
This should bring the maximum memory usage down to 4096 x 8KB = 32768KB,
which is a better figure than bup-0.25's average in the large file
tests, and would also be one of the better results in the small file
tests.
However, reducing the buffer that low is likely to impact other results, such
as backup speed, because the client will be waiting on the server more often.
Consequently, more experimentation is required in order to find a satisfactory
balance.
 < Prev
Contents
Next >
< Prev
Contents
Next >
|
