Improved Open Source Backup:
Incorporating inline deduplication and sparse indexing solutions
G. P. E. Keeling
< Prev
Contents
Next >
Appendix E - Design of the second iteration
The documents that were originally written for the second iteration were not
quite right,
and needed to be modified due to some slight misconceptions from earlier
designs.
After the first iteration, I realised that the storage format was
not quite right. There is a server 'champion chooser' module now required for
the second iteration, which selects lists of signatures to duplicate on, given
a collection of hooks from the client. To select the signatures to load, it
has a 'sparse index' of hooks in memory.
I had imagined that it could load the signatures from the signature
store in the previous design, which would map directly to the blocks in the
block store.
However, this was not right, because after multiple backups, the signatures in
the signature store start to lose the property of locality as deduplication
takes effect, since only new blocks get added to the data store.
Instead, the champion chooser needs to use sparse indexes on the manifest of
each backup. That is, the actual sequence of blocks as they appeared in each
backup, rather than the compacted data in the block store.
This also means that there is no longer any need for the 'signature store' in
the previous design, since nothing looks at it any more.
So, there follows a slightly modified version of the original design for
the second iteration.
First, an updated high level diagram of the intended backup data
flow around the client and server, showing the major components and their
inputs and outputs.
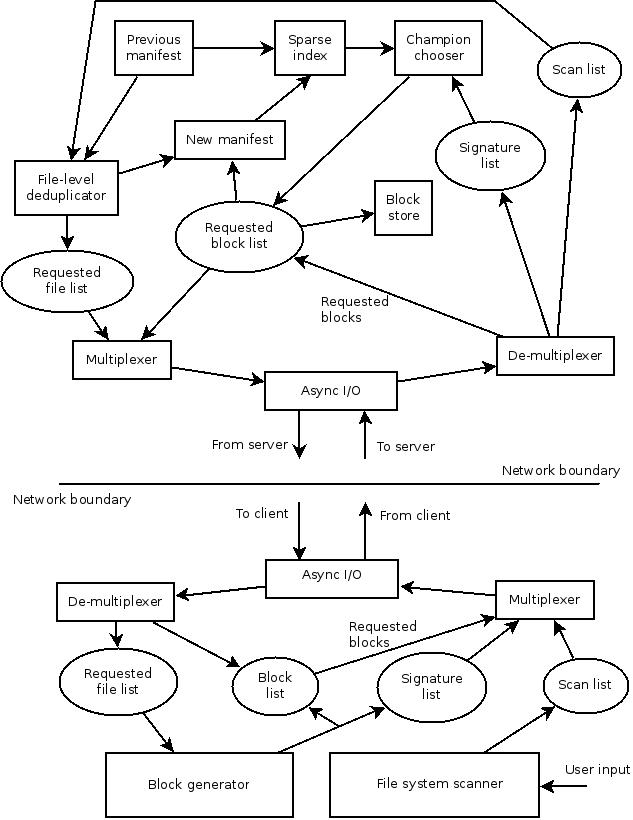
E.1. Network data streams
The data streams remained the same as in the first iteration for both backup
and restore.
E.2. Scanning the client file system
This also remained the same. In fact, there were no design changes at all for
the client.
E.3. Storage format
In order to allow deduplication across multiple different clients, the
directory structure for backup storage now looks like this:
<group>/data/
<group>/data/sparse
<group>/data/0000/0000/0000
<group>/data/0000/0000/0001 (and so on)
<group>/clients/<name>/<backup number>/manifest/
<group>/clients/<name>/<backup number>/manifest/sparse
<group>/clients/<name>/<backup number>/manifest/00000000
<group>/clients/<name>/<backup number>/manifest/00000001 (and so on)
Clients can be configured to have different deduplication groups, and can
thereby share saved blocks. When opening files in the 'data' directory for
writing, the server now needs to get a lock before doing so, since more than
one child process could be trying to open the same file.
Due to the need for the 'champion chooser' module to index the manifests from
each backup, the manifest files are now broken down into multiple files,
containing a maximum of 4096 signatures each. They still have the same
internal format as described in the first iteration.
At the end of each backup, a sorted sparse index for each of the manifest
components is generated, and the 'sparse' file in the manifest directory
is updated to contain all of them. This file is then merged into the 'sparse'
file in the 'data' directory for the group. If there are entries with
identical hooks, the more recent manifest component is chosen.
The following is an example of the format of the 'sparse' files. The paths
are always relative to whatever the root directory is. This ensures that
backup group directories can be copied to other locations at anytime without
causing path problems.
M0042global/clients/black/0000005 2013-10-22 16:44:54/manifest/0000022F
F0010F00008A155DF4307
F0010F00258BF988BFC28
...
M0042global/clients/white/0000003 2013-10-10 00:04:22/manifest/00000198
F0010F000182980D81EEC
F0010F000227AB578BE4C
...
The 1 character plus 4 character syntax at the beginning of line follows the
strategy described previously.'M' means 'path to manifest component', and 'F'
means 'fingerprint'. Duplicate fingerprints ('hooks') within an index are
removed.
The rabin fingerprints chosen for the hooks are those that
start with 'F'. This generally gives between 200 and 300 hooks for each
manifest component. Since there are 4096 signatures in each manifest component,
this reduces the memory requirement for the index to about 1/16.
At some future point, this can
be halved if the software is modified to pack the fingerprints into
4 bits per character. Additionally, fewer hooks could be chosen per manifest
component for more memory reduction. However, just choosing those that begin
with 'F' is enough for the current project.
E.4. Champion chooser
The champion chooser module takes the sparse index (generated from previous
manifests) as an input, plus a sequence of incoming hooks from the client.
The server program waits until enough signatures (currently 4096, or no more
left to receive) have been received before running the main champion chooser
code.
The champion chooser needs to choose the manifest component that contains
the largest number of hooks in the sequence from the client. When it has done
so, it needs to repeat the procedure to choose another, but exclude hooks
from already chosen manifest components. Then repeat again, X
number of times, or until all the hooks have been chosen. Crucially, all this
needs to be fast.
In memory, the fingerprint hooks are converted to uint64 types and are used as
the indexes for 'sparse' structs making up entries in a hash table.
Each struct contains an array of pointers to candidate manifest component
entries. When a hook is added from a candidate, a new 'sparse' struct is added
if one didn't already exist for the hook, and a pointer to the relevant
candidate is added to array.
The candidate manifest components are structures containing the
path to the component, and a uint16 pointer for its score - the content of
the pointer is contained in a separate array, which means that the scores
array can be very quickly reset without needing to iterate over all the
candidates.
Each incoming hook structure from the client has a pointer to a uint8 type
called 'found',
which indicates whether a candidate has been chosen that contains this hook.
Again, this points to an entry in a separate array, so that resetting these
values is just a matter of setting the contents of the array to zero, rather
than having to iterate over all the incoming components.
When it is time to choose the set of champions, the incoming 'found' array
is reset.
Then, while not enough champions manifest components have been found,
the scores are reset, and the incoming hooks are iterated over. If an incoming
hook's 'found' field is set, it is skipped. Note that none of the 'found'
fields have yet been set for hooks from the immediately previous iteration.
If a hook is found in the hash table, the scores of all the candidates that
contain that hook are incremented in turn.
A pointer to the highest scoring candidate is maintained as the scores
are incremented.
If a candidate pointer is arrived at that is the same as the immediate
previously found manifest, the incoming hook's 'found' field is set, and
any incremented scores that were set on its candidates are reset. This
excludes previously accounted for hooks from the score, and since the 'found'
field is now set, subsequent passes discount them faster.
After iterating over the incoming hooks, the highest scoring candidate manifest
component is chosen to be loaded into memory via its path component. As this
contains all the signatures from that candidate and not just the hooks, the
server now has a reasonable set of signatures with which to deduplicate
incoming blocks.
If not enough champions have been found, the incoming hooks are iterated over
again.
As this requires only one file to be open and read for each candidate chosen,
the problem of the disk deduplication bottleneck has been significantly
reduced.
Finally, an important feature to note is that the server needs to continually
add manifest components from the current backup in progress as
candidates. Otherwise, the first backup would potentially store far more data
than necessary, as it has nothing to deduplicate against. Subsequent
backups would be able to deduplicate against previous ones, but not themselves.
< Prev
Contents
Next >
|
